
Vraag 1
A) businessidee & zoektermen
Het businessidee dat wij onderzoeken is dat restaurantkertens meestal niet over een eigen IT-afdeling beschikt, maar heeft wel nood aan centrale personeelsplanning, voorraadbeheer en realtime inzicht in rendabiliteit per vestiging. We vragen ons af of dit weldegelijk zo is.
Businessidee: Is er een stijgende interesse naar digitale horeca-oplossingen zoals online reservatiesystemen en personeelsplanning voor horecazaken?
Vlaanderen / Nederland
- Horecasoftware
- Online Reservatie
- Kassasysteem
Frankrijk / Wallonië
- Horecasoftware
- Réservation online
- Caisse enrigistreuse
B) Trendanalyse
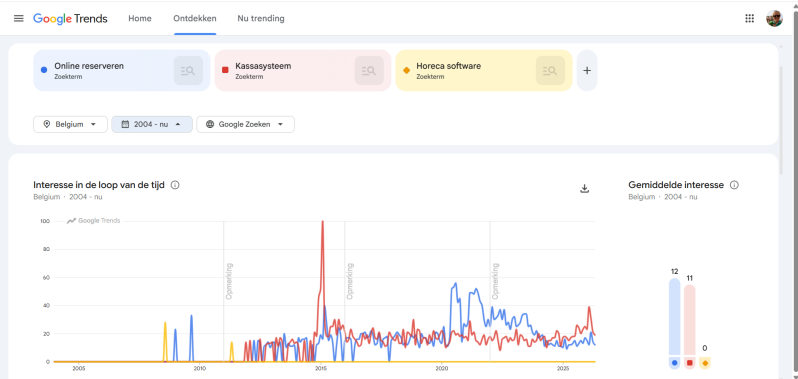
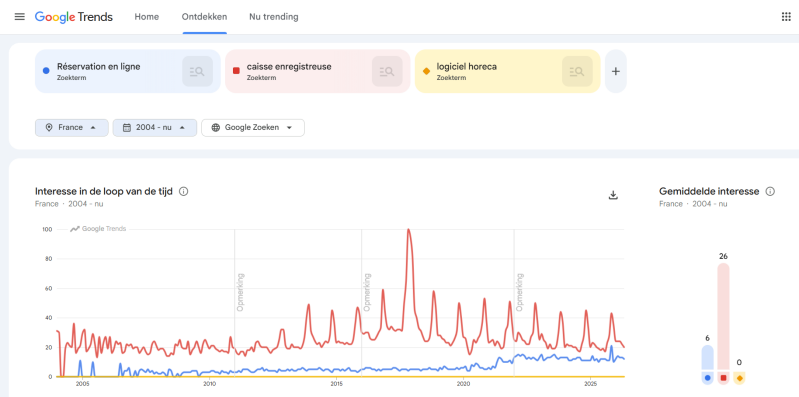
Uit Google Trends blijkt dat zoektermen zoals “horeca software” en “online reservatie restaurant” de afgelopen 10 jaar een stijgende trend vertonen in zowel Vlaanderen als Nederland.
De interesse stijgt vooral vanaf 2020, wat verklaard kan worden door:
- de digitalisering van de horecasector,
- online reservaties na COVID,
- de nood aan efficiëntere personeelsplanning,
- en stijgende loonkosten binnen horeca.
In Nederland ligt het zoekvolume doorgaans hoger dan in Vlaanderen. Dit kan verklaard worden door een grotere markt en een sterkere digitalisering binnen de Nederlandse horecasector.
In Franstalige regio’s zien we vergelijkbare trends voor zoektermen zoals “réservation restaurant en ligne”, al ligt het zoekvolume iets lager dan in Nederlandstalige regio’s.
Conclusie:
De interesse in digitale horeca-oplossingen vertoont een structureel stijgende trend, wat erop wijst dat er een groeiende markt bestaat voor cloudgebaseerde horeca-platformen.
Verschillen:
C) Seasonality:
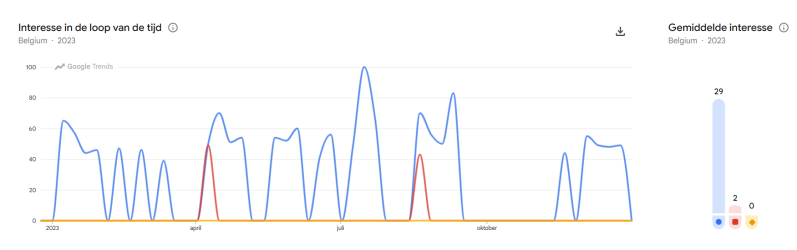
De Google Trends-data toont een duidelijke seasonality voor de zoekterm “online reserveren”. De interesse stijgt vooral tijdens de lente- en zomermaanden. Dit kan verklaard worden doordat consumenten tijdens deze periodes vaker restaurants bezoeken, vakanties plannen en uitstappen reserveren. In de wintermaanden ligt de zoekinteresse doorgaans lager, behalve rond feestperiodes zoals Kerstmis en Nieuwjaar. De terugkerende patronen over meerdere jaren wijzen op een stabiele en voorspelbare seizoensgebondenheid.
Voorbeeld België 2023:
D) Geografische verschillen:
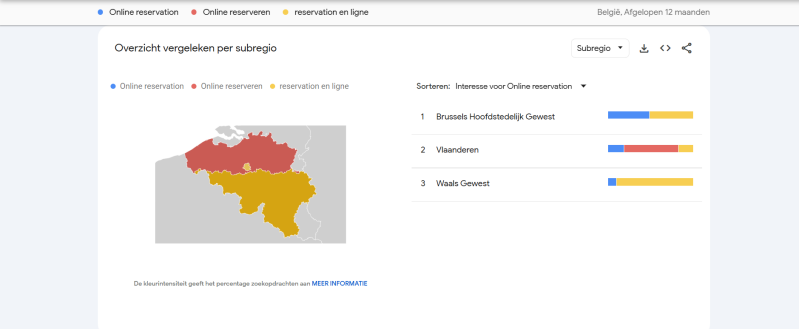
De geografische analyse van Google Trends toont duidelijke regionale verschillen afhankelijk van de gebruikte taal van de zoekterm. Voor de Nederlandstalige zoekterm “online reserveren” ligt de hoogste zoekinteresse voornamelijk in Vlaanderen. Dit is logisch aangezien Nederlands daar de dominante taal is. Voor de Franstalige zoekterm “reservation en ligne” bevindt de grootste interesse zich in Wallonië en gedeeltelijk in Brussel, waar Frans de meest gebruikte taal is. Opvallend is dat de Engelstalige zoekterm “online reservation” vooral sterk scoort in het Brussels Hoofdstedelijk Gewest. Dit kan verklaard worden door het internationale karakter van Brussel, waar veel expats, toeristen en anderstalige inwoners Engels gebruiken bij online zoekopdrachten. De resultaten tonen aan dat zoekgedrag sterk afhankelijk is van taal en regio. Voor een digitaal reservatieplatform binnen de horecasector is het daarom belangrijk om meertalige ondersteuning en gerichte marketing per regio te voorzien.
Conclusie:
Vlaanderen vormt de meest interessante regio voor een Nederlandstalig online reservatieplatform, terwijl Brussel extra potentieel biedt voor Engelstalige gebruikers.
Vraag 2: Experiment met AI tooling op big data

2. Verkenning – Welke van de 5 V’s van Big Data zie je hier terug en waarom?
Volume
De dataset bevat 10.000 klantreviews met meerdere kolommen zoals ratings, titels, reviewteksten en productcategorieën. Dit zorgt voor een grote hoeveelheid data die moeilijk manueel te analyseren is, maar geschikt is voor automatische verwerking en analyse.
Variety
De data bestaat uit verschillende soorten informatie:
- numerieke data (ratings),
- tekstuele data (review titles en review texts),
- categorische data (productcategorieën).
Daardoor bevat de dataset zowel gestructureerde als ongestructureerde data.
Velocity
Klantreviews worden in de praktijk voortdurend gegenereerd wanneer klanten online aankopen doen en feedback achterlaten. Hoewel deze dataset statisch is, vertegenwoordigt ze een proces waarbij data continu blijft groeien.
Veracity
Niet alle reviews zijn volledig betrouwbaar of objectief. Sommige reviews kunnen overdreven positief of negatief zijn, weinig informatie bevatten of gebaseerd zijn op persoonlijke emoties. Dit kan invloed hebben op de nauwkeurigheid van analyses.
Value
Uit de reviews kan waardevolle informatie gehaald worden over:
- klanttevredenheid,
- productkwaliteit,
- levering,
- klantenservice,
-
en terugkerende problemen.
Bij deze de link naar het excel-bestand voor resultaten: bigdata_reviews_artevelde_10000.csv.xlsx
Bij deze de link naar het excel-bestand na resultaten: bigdata_reviews_artevelde.xlsx
De 5 V's van Big Data: samenvatting
Wat is de opdracht? We analyseren een dataset van 10.000 productreviews en onderzoeken welke van de klassieke 5 V's van Big Data hierin herkenbaar zijn.
Volume is aanwezig: 10.000 rijen met 10 kolommen zijn voor een mens onmogelijk handmatig te verwerken. In productieomgevingen spreken we over miljoenen reviews per dag.
Variety is duidelijk zichtbaar: de dataset combineert gestructureerde data (rating, datum, land, kanaal) met volledig ongestructureerde vrije tekst (review_title, review_text) in meerdere talen. Ook de verkoopkanalen variëren: webshop, marktplaats en in-store kiosk.
Velocity is impliciet aanwezig: de reviews zijn gespreid over meerdere jaren en komen uit verschillende kanalen tegelijk. In een live systeem stromen ze realtime binnen, wat batchverwerking onvoldoende maakt.
Veracity was bij deze opdracht letterlijk voelbaar: het CSV-bestand bleek technisch corrupt — elke datarij stond ingepakt als één enkel veld, waardoor standaardtools faalden. Daarnaast bevatten reviewteksten sjabloontaal ("er is nog ruimte voor verbetering") die de analytische waarde vermindert. Dit illustreert hoe kwaliteitscontrole essentieel is bij Big Data.
Value is de uiteindelijke reden waarom we dit doen: uit 10.000 reviews kunnen we afleiden welke productcategorieën slecht scoren, waar leveringsproblemen structureel zijn en welke klantsegmenten het meest kritisch zijn — inzichten die handmatig onhaalbaar zijn maar direct sturen op bedrijfsbeslissingen.
Conclusie: Alle 5 V's zijn aanwezig in deze dataset. Opvallend is dat Veracity niet theoretisch bleef maar zich meteen manifesteerde bij het inladen van het bestand zelf — een realistische voorproef van wat data-engineers dagelijks tegenkomen.
Vraag 3: Data source brainstorm, een SmartCity in Nederland
1. Korte research: Smart City Amsterdam
Amsterdam is een sterke Nederlandse Smart City omdat de stad inzet op slimme mobiliteit, open data, crowd monitoring, duurzaamheid en digitale stadsprocessen. De gemeente heeft een centraal dataportaal, Data Amsterdam, met actuele en betrouwbare stadsgegevens. Daarnaast bestaat het platform Amsterdam Smart City, waar projecten rond energie, mobiliteit, circulariteit en digitalisering worden gedeeld.
Gebruikte internetbronnen:
- Data Amsterdam: centraal dataportaal van de gemeente Amsterdam.
- Amsterdam Smart City: projecten rond smart mobility, energie en digitalisering.
- Sensoren Crowd Monitoring Systeem Amsterdam: voetgangers- en fietsersstromen.
- Public Eye / Druktebeeld: camera’s tellen personen, beelden worden niet getoond maar aantallen doorgestuurd.
- NDW Open Data: actuele verkeersdata, reistijden, snelheden, laadpunten en wegwerkzaamheden.
- OV Data / GTFS Nederland: geplande en actuele OV-data.
2. Identificatie van Big Data-bronnen
Amsterdam beschikt over verschillende soorten Big Data-bronnen die gebruikt worden binnen het Smart City-beleid. Een eerste belangrijke bron zijn luchtkwaliteitssensoren die verspreid staan over de stad, bijvoorbeeld aan straatverlichting of gebouwen. Deze sensoren meten gegevens zoals stikstofdioxide (NO₂), fijnstof (PM2.5 en PM10), temperatuur en luchtvochtigheid. De output van deze databron bestaat bijvoorbeeld uit meetwaarden in microgram per kubieke meter (µg/m³). Deze bron behoort tot de categorie sensoren en Internet of Things (IoT).
Een tweede databron zijn de slimme camera’s van het Public Eye-systeem. Deze camera’s worden gebruikt voor crowd monitoring en detecteren automatisch hoeveel mensen zich in een bepaalde zone bevinden. De data-output bestaat bijvoorbeeld uit het aantal personen per minuut of waarschuwingen wanneer een locatie te druk wordt. Deze databron behoort tot de categorie computer vision en AI-verwerking van visuele data.
Daarnaast maakt Amsterdam gebruik van het Crowd Monitoring Systeem Amsterdam (CMSA), waarbij sensoren en telpunten fietsers en voetgangers registreren. Deze systemen genereren data zoals het aantal fietsers of voetgangers per locatie en per tijdsinterval. Deze databron valt onder de categorie mobiliteits- en verkeerssensoren.
Een vierde belangrijke databron is de real-time openbaarvervoerdata via GTFS en GTFS-Realtime feeds. Hiermee worden gegevens verzameld over trams, metro’s, bussen en treinen. Voorbeelden van data-output zijn voertuiglocaties, vertragingen in seconden en verwachte aankomsttijden. Deze bron behoort tot de categorie operationele transportdata.
Tot slot gebruikt Amsterdam ook NDW-verkeersdata en infrastructuurdata. NDW verzamelt gegevens over verkeer, files, snelheden en laadpunten voor elektrische voertuigen. Voorbeelden van data-output zijn gemiddelde snelheid per wegsegment, reistijden en meldingen van verkeersdrukte. Deze databron behoort tot de categorie verkeers- en infrastructuurdata.
3. Karakterisering met de 3 Basis-V’s
Bron A: Crowd Monitoring Systeem Amsterdam
Volume:
Stel dat 300 telpunten elke minuut een telling registreren. Dat geeft 300 × 1.440 = 432.000 metingen per dag. Met tijdstip, locatie, richting en telling kan dit oplopen tot tientallen tot honderden MB per dag.
Velocity:
Hoog. De data wordt quasi real-time of met korte intervallen gegenereerd, omdat drukte in straten, pleinen of fietsroutes snel verandert.
Variety:
Vooral gestructureerde tijdreeksdata: tijdstip, locatie, telling, richting. Eventueel aangevuld met semi-gestructureerde metadata zoals sensor-ID, locatiecoördinaten en status van het telpunt.
Bron B: Public Eye / slimme druktecamera’s
Volume:
Als alleen tellingen worden opgeslagen, blijft het volume relatief beperkt. Als videobeelden tijdelijk worden verwerkt, kan het volume zeer groot zijn: meerdere GB per camera per dag.
Velocity:
Zeer hoog. Camera’s leveren continu beeldinput, en algoritmes moeten snel tellen hoeveel mensen aanwezig zijn zodat stadsmedewerkers drukte kunnen reguleren.
Variety:
Ongestructureerde data: videobeeld.
Semi-gestructureerde data: AI-events zoals “drukte boven drempelwaarde”.
Gestructureerde data: aantal personen per locatie en tijdstip.
4. Veracity: risico en maatregel
Gekozen bron: Public Eye / slimme druktecamera’s.
Risico van lage Veracity:
Het algoritme kan mensen fout tellen bij regen, schaduw, drukke groepen, obstakels of slechte camerahoek. Daardoor kan de stad denken dat een plek drukker of rustiger is dan werkelijk het geval is.
Maatregel:
Regelmatige validatie met handmatige steekproeven, kalibratie van camera’s, kwaliteitslabels per meting en automatische detectie van afwijkende waarden.
5. Value: waardecreatie voor Amsterdam
Door crowd monitoring, OV-data en NDW-verkeersdata te combineren kan Amsterdam drukte en mobiliteit beter sturen. Dit levert niet alleen financiële waarde op, maar ook leefbaarheid, veiligheid en duurzaamheid.
Mogelijke KPI’s:
- 10% minder gemiddelde reistijd tijdens piekuren op drukke routes.
- 15% minder overdrukte situaties in populaire gebieden.
- 5% hogere OV-punctualiteit door betere afstemming met actuele verkeersdrukte.
- 10% minder CO₂-uitstoot in drukke zones door betere verkeersspreiding.
- Kortere incidentduur, bijvoorbeeld gemiddeld 5 minuten sneller ingrijpen bij gevaarlijke drukte.
6. Conclusie
Amsterdam is een geschikte Nederlandse Smart City-casus. De stad gebruikt databronnen uit verschillende categorieën: sensoren, camera’s, mobiliteitsdata, OV-data en verkeersinfrastructuur. Door aandacht te besteden aan Volume, Velocity, Variety, Veracity en Value kan Amsterdam data inzetten voor een veiligere, duurzamere en beter bereikbare stad.
Maak jouw eigen website met JouwWeb